InNetflix TechBlogbyNetflix Technology BlogIntroducing Impressions at NetflixPart 1: Creating the Source of Truth for ImpressionsFeb 159Feb 159
Zhenzhong XuThe Four Innovation Phases of Netflix’s Trillions Scale Real-time Data InfrastructureFeb 1, 202220Feb 1, 202220
InData Engineer ThingsbyVu TrinhWe might not fully understand the column store!A note on the Row, Column, and Hybrid storage modelDec 14, 20242Dec 14, 20242
InTDS ArchivebyCai Parry-JonesData Quality Doesn’t Need to Be ComplicatedThree Zero-Cost Solutions That Take Hours, Not MonthsDec 10, 202411Dec 10, 202411
InLevel Up CodingbyArman Hossen11 Python Libraries That Will 10x Your Development Speed in 2024: A Data-Driven Analysis11 Game-Changing Python Libraries You’ve Been Missing in 2024Dec 3, 202410Dec 3, 202410
Hugo LuManaging Snowflake Infrastructure with dbt and TerraformUnderstanding where to draw the boundaries around dbt is importantOct 6, 2024Oct 6, 2024
InGoogle Cloud - CommunitybyOscar PulidoStop Thinking in Data Pipelines, Think in Data Platforms: Introducing the Analytics Engineering…Imagine a world where you could deploy your entire enterprise-ready data platform in minutes and empower your data practitioners to…Oct 28, 20245Oct 28, 20245
Prem Vishnoi(cloudvala)TikTok Data Engineer Interview ProcessTikTok, with its rapidly growing user base of over 1 billion and new business eg e-commerce as well , offers an exciting environment for…Sep 21, 20243Sep 21, 20243
Netflix Technology BlogETL development life-cycle with Dataflowby Rishika Idnani and Olek GorajekAug 2, 20246Aug 2, 20246
InTDS ArchivebyCai Parry-JonesRadical Simplicity in Data EngineeringLearn from Software Engineers and Discover the Joy of ‘Worse is Better’ ThinkingJul 26, 20244Jul 26, 20244
InNetflix TechBlogbyNetflix Technology BlogMaestro: Netflix’s Workflow OrchestratorBy Jun He, Natallia Dzenisenka, Praneeth Yenugutala, Yingyi Zhang, and Anjali NorwoodJul 22, 202412Jul 22, 202412
InIn the PipelinebyDave FlynnHow to use a Makefile to speed up your dbt project workflowLearn how to use a makefile to reduce dbt command fatigue and group related commands for easy reuse and sharing.Jun 13, 20242Jun 13, 20242
InTDS ArchivebyPatrick HoeflerDask DataFrame is Fast NowHow Dask enables processing data at terabyte scale efficientlyMay 27, 2024May 27, 2024
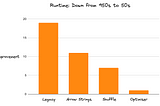
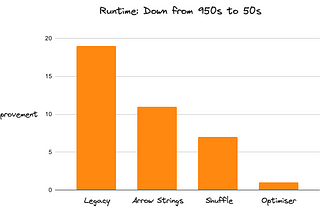
InTDS ArchivebyDario RadečićPython One Billion Row Challenge — From 10 Minutes to 4 SecondsThe one billion row challenge is exploding in popularity. How well does Python stack up?May 8, 202460May 8, 202460
InData Engineer ThingsbyVu TrinhI spent 5 hours understanding more about the Delta Lake table formatAll insights from the paper: Delta Lake: High-Performance ACID Table Storage over Cloud Object StoresMay 4, 20242May 4, 20242
Sean CoyneData Engineering: Practice System Design Question and Solution: BatchOne common type of data engineering system design question is the batch process pipeline, with any system design question there are many…Nov 8, 20231Nov 8, 20231
InTDS ArchivebyJoão PedroMy First Billion (of Rows) in DuckDBFirst Impressions of DuckDB handling 450Gb in a real projectMay 1, 202412May 1, 202412
InTDS ArchivebyDario RadečićDuckDB and AWS — How to Aggregate 100 Million Rows in 1 MinuteProcess huge volumes of data with Python and DuckDB — An AWS S3 example.Apr 25, 20248Apr 25, 20248